![]()
3.5. Exercise 4: Mapping Wildfire Susceptibility in the Liguria Region with Simple Machine Learning Classifiers#
Credits
This online tutorial would not be possible without invaluable contributions from Andrea Trucchia (reduced data, methods), Giorgio Meschi (code, methods), and Marj Tonini (presentation, methods). The methodology builds upon the following article:
which generalizes the study below from the Liguria region (our case study) to all of Italy:
In week 3’s final notebook, we will train classifiers on real wildfire data to map the fire risk in different regions of Italy. To keep the data size manageable, we will focus on the coastal Liguria region that experiences a lot of wildfires, especially during the winter.
3.5.1. Machine Learning for Environmental Risk Analysis#
For environmental sciences practioners, one of the scenarios where machine learning can be particularly useful is risk analysis. Environmental risk analysis involves predicting where potential hazards may occur; it also involves understanding why some regions are more vulnerable to hazards than others. Machine learning models can be useful for these tasks because they can analyze large datasets containing different environmental predictors (e.g., weather conditions, soil conditions etc.) in an effective manner. By learning the hidden links between predictors and hazard risks, we may also gain new insights on what predictors or patterns are useful for creating early hazard warning systems.
In this exercise, we ask you to use the machine learning classifiers we learned in this chapter to recreate wildfire susceptibility maps for the Liguria region of Italy. The basic idea is to use ML classifiers to analyze a dataset with observations in weather conditions, vegetation cover, and topography information. The goal will be to understand how different factors enhance or reduce the probability of firefire in Liguria, which can help authorities and decision-makers to apply resources to critical areas for hazard prevention.

Caption: A wildfire in Italy. Can we predict which locations are most susceptible to wildfires using simple classifiers? 🔥
Source: ANSA
Let’s start by downloading and loading the datasets into memory using the pooch, pickle5, and GeoPandas libraries:
# Install geopandas and pickle5
%pip install geopandas
%pip install pickle5
Requirement already satisfied: geopandas in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (0.14.0)
Requirement already satisfied: fiona>=1.8.21 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from geopandas) (1.9.4.post1)
Requirement already satisfied: packaging in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from geopandas) (23.1)
Requirement already satisfied: pandas>=1.4.0 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from geopandas) (2.0.3)
Requirement already satisfied: pyproj>=3.3.0 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from geopandas) (3.6.0)
Requirement already satisfied: shapely>=1.8.0 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from geopandas) (2.0.2)
Requirement already satisfied: attrs>=19.2.0 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from fiona>=1.8.21->geopandas) (21.4.0)
Requirement already satisfied: certifi in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from fiona>=1.8.21->geopandas) (2023.5.7)
Requirement already satisfied: click~=8.0 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from fiona>=1.8.21->geopandas) (8.1.4)
Requirement already satisfied: click-plugins>=1.0 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from fiona>=1.8.21->geopandas) (1.1.1)
Requirement already satisfied: cligj>=0.5 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from fiona>=1.8.21->geopandas) (0.7.2)
Requirement already satisfied: six in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from fiona>=1.8.21->geopandas) (1.16.0)
Requirement already satisfied: importlib-metadata in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from fiona>=1.8.21->geopandas) (6.8.0)
Requirement already satisfied: python-dateutil>=2.8.2 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from pandas>=1.4.0->geopandas) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from pandas>=1.4.0->geopandas) (2023.3)
Requirement already satisfied: tzdata>=2022.1 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from pandas>=1.4.0->geopandas) (2023.3)
Requirement already satisfied: numpy>=1.20.3 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from pandas>=1.4.0->geopandas) (1.25.1)
Requirement already satisfied: colorama in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from click~=8.0->fiona>=1.8.21->geopandas) (0.4.6)
Requirement already satisfied: zipp>=0.5 in c:\users\tbeucler\.conda\envs\jb\lib\site-packages (from importlib-metadata->fiona>=1.8.21->geopandas) (3.16.0)
Note: you may need to restart the kernel to use updated packages.
Collecting pickle5
Using cached pickle5-0.0.11.tar.gz (132 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
Building wheels for collected packages: pickle5
Building wheel for pickle5 (setup.py): started
Building wheel for pickle5 (setup.py): finished with status 'error'
Running setup.py clean for pickle5
Failed to build pickle5
Note: you may need to restart the kernel to use updated packages.
error: subprocess-exited-with-error
python setup.py bdist_wheel did not run successfully.
exit code: 1
[17 lines of output]
running bdist_wheel
running build
running build_py
creating build
creating build\lib.win-amd64-cpython-39
creating build\lib.win-amd64-cpython-39\pickle5
copying pickle5\pickle.py -> build\lib.win-amd64-cpython-39\pickle5
copying pickle5\pickletools.py -> build\lib.win-amd64-cpython-39\pickle5
copying pickle5\__init__.py -> build\lib.win-amd64-cpython-39\pickle5
creating build\lib.win-amd64-cpython-39\pickle5\test
copying pickle5\test\pickletester.py -> build\lib.win-amd64-cpython-39\pickle5\test
copying pickle5\test\test_pickle.py -> build\lib.win-amd64-cpython-39\pickle5\test
copying pickle5\test\test_picklebuffer.py -> build\lib.win-amd64-cpython-39\pickle5\test
copying pickle5\test\__init__.py -> build\lib.win-amd64-cpython-39\pickle5\test
running build_ext
building 'pickle5._pickle' extension
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for pickle5
ERROR: Could not build wheels for pickle5, which is required to install pyproject.toml-based projects
import geopandas as gpd
import numpy as np
import pickle5 as pickle
import pooch
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[2], line 3
1 import geopandas as gpd
2 import numpy as np
----> 3 import pickle5 as pickle
4 import pooch
ModuleNotFoundError: No module named 'pickle5'
# Function to load the data
def load_data(path):
# Load the content of the pickle file (using pickle5 for Google Colab)
with open(path, "rb") as fh:
points_df = pickle.load(fh)
# Convert it to a Geopandas `GeoDataFrame` for spatial analysis
points_df = gpd.GeoDataFrame(points_df,
geometry=gpd.points_from_xy(np.float64(points_df.x),
np.float64(points_df.y)))
return points_df
# Path to the data in UNIL OneDrive
variables_path = pooch.retrieve('https://unils-my.sharepoint.com/:u:/g/personal/tom_beucler_unil_ch/EU4FQkuYknFDiDfd7droyAcBP0qFOR5-c-_Oq74gjhTGwQ?download=1',
known_hash='e8ebc70f972b5af4ef3d6110dcd61ce01ce5a830dcdb7d2c9e737aeab781606c')
wildfires_path = pooch.retrieve('https://unils-my.sharepoint.com/:u:/g/personal/tom_beucler_unil_ch/EcjqeERsnIRHjhcx1ZFVNggBS7nPUkW530XRrpVUB-qnOw?download=1',
known_hash='361f067aafbac8add8f8a9a5c630df3c962cd37a2f125f420e7b9330fd0a1a4c')
Downloading data from 'https://unils-my.sharepoint.com/:u:/g/personal/tom_beucler_unil_ch/EU4FQkuYknFDiDfd7droyAcBP0qFOR5-c-_Oq74gjhTGwQ?download=1' to file '/root/.cache/pooch/07ef52a70acfc4230ffc4d0ca1624c7a-EU4FQkuYknFDiDfd7droyAcBP0qFOR5-c-_Oq74gjhTGwQ'.
Downloading data from 'https://unils-my.sharepoint.com/:u:/g/personal/tom_beucler_unil_ch/EcjqeERsnIRHjhcx1ZFVNggBS7nPUkW530XRrpVUB-qnOw?download=1' to file '/root/.cache/pooch/083c82ff55a8a8a6c98e76bf347a96ef-EcjqeERsnIRHjhcx1ZFVNggBS7nPUkW530XRrpVUB-qnOw'.
# Load the data and convert it to a GeoPandas `GeoDataFrame`
# This can take a minute
variables = load_data(variables_path)
wildfires = load_data(wildfires_path)
3.5.1.1. Part I: Pre-Processing the Dataset for Classification#
Q1) After analyzing the topography and land cover data provided in variables, create your input dataset inputs from variables to predict the occurence of wildfires (wildfires). Keep at least one categorical variable (veg, bioclim, or phytoclim).
Hint 1: Refer to the documentation at this link to know what the different keys of variables refer to.
Hint 2: You may refer to Table 1 of Tonini et al., copied below, to choose your input variables, although we recommend starting with less inputs at first to build a simpler model and avoid overfitting.

Here are some pandas commands you could use to explore your data. .head() .columns() .describe()
# Explore the `variables` dataset
#########################################################################################################
# 1. What kind of data is provided in the "variables" panda DataFrame?
#########################################################################################################
# Can you print the variable names?
print(variables._______)
# Can you print a table with all the statistics of each variable in the dataframe?
print(variables._________)
There are 25 columns (variables) in the DataFrame. It is probably best to start simple and just use a few variables to make the wildfire prediction.
Can we use a very simple model to predict wildfires ❓
A simple model might contain dem, slope, veg and bioclim. We can use it as a baseline to evaluate model performance when you use other combinations to train the model.
However, we cannot tell you which combination would perform the best as we have not done an extensive search while preparing the notebook.
# Here you will filter the DataFrame so that only the variables you want are in the input
############################################################################################################
# 1. Drop down the names of variables you want here so that pandas can do the filtering for you.
############################################################################################################
vars_tokeep = [___,____,____,__name__]
############################################################################################################
# 2. Create a new dataframe 'inputs' with just the variables you want
############################################################################################################
inputs = variables[_______] # Filter 'variables' dataframe
inputs.head # print the first few columns to make sure everything works fine
<bound method NDFrame.head of dem slope veg bioclim
point_index
0 563 20.843185 34 15
1 527 23.599121 34 15
2 525 26.699856 34 15
3 519 24.512413 34 15
4 532 20.421495 34 15
... ... ... .. ...
519336 125 29.669502 37 0
519386 139 23.541714 32 0
519388 113 16.290375 32 0
519422 95 23.240271 37 0
519423 67 15.023369 32 0
[528669 rows x 4 columns]>
Q2) To avoid making inaccurate assumptions about which types of vegetation and non-flammable area are most similar, convert your categorical inputs into one-hot vectors.
Hint 1: You may use the fit_transform method of scikit-learn’s OneHotEncoder class to convert categorical inputs into one-hot vectors.
Hint 2: Don’t forget to remove the categorical variables from your input dataset, e.g. using drop if you are still using a GeoDataFrame, or del/pop if you are working with a Python dictionary.
Hint 3: There are numerous ways to change the categorical data into one-hot vectors. It is quite easy to do in pandas, but scikit-learn also provides some transformers that could be useful, including .ColumnTransformer() and Pipeline().
In the guided reading, you have seen how these functions are used. Try experiment with them and see if you prefer using these scikit transformers or pandas.
############################################################################################################
# 1. Import OneHotEncoder for 'veg' and 'bioclim' data, and pandas
############################################################################################################
from sklearn._____________ import OneHotEncoder
import pandas as pd
############################################################################################################
# 2. Initiate OneHotEncoder object, set the 'sparse' option to False
############################################################################################################
enc = OneHotEncoder(____=____)
############################################################################################################
# 3. Convert categorical variables into one-hot vectors
############################################################################################################
# Convert categorical variables with 'enc'
veg_onehot = enc.__________(variables[[______]])
bioclim_onehot = enc.__________(variables[[______]])
# Convert 'veg_onehot' and 'bioclim_onehot' to pandas DataFrames
veg_transform = _____________(________) # veg
bio_transform = _____________(________) # bioclim
############################################################################################################
# 4. Print the shape of 'veg_transform'
############################################################################################################
print(_______________)
# Don't change these!
veg_transform= veg_transform.add_prefix('v_')
bio_transform= bio_transform.add_prefix('b_')
Input (528669, 7)
############################################################################################################
# 5. Convert 'inputs' into Panda DataFrame
############################################################################################################
inputs_gdf = ___________(_____)
############################################################################################################
# 6. Add 'veg_transform' and 'bio_transform' into the inputs DataFrame
############################################################################################################
inputs_gdf = inputs_gdf.___(___________)
inputs_gdf = inputs_gdf.___(____________)
############################################################################################################
# 7. Use .drop() to delete 'veg' and 'bioclim' from DataFrame
############################################################################################################
inputs_gdf.drop(_____=[____,_____])
Now that we built our inputs dataset, we are ready to build our outputs dataset!
Q3) Using the point_index column of wildfires and variables, create your outputs dataset, containing 1 when there was a wildfire and 0 otherwise.
Hint: Check that inputs and outputs have the same number of cases by looking at their .shape[0] attribute.
#####################################################################################################################
# 1. Use numpy to initialize an outputs array with the same shape as the 'point_index' column in the variables table
#####################################################################################################################
outputs = np.zeros_like(_______[________])
#####################################################################################################################
# 2. Pull out the indices of wildfire locations from the pandas DataFrame 'wildfires'
#####################################################################################################################
wildfiresindex = ________.______
#####################################################################################################################
# 3. Fill the zero array with ones if a fire broke out at a specific location index.
# Here you can use a for loop for this task
#####################################################################################################################
for ___ in ____________:
outputs[___] = 1
#####################################################################################################################
# 4. Check that `inputs` and `outputs` have the same shape[0]
#####################################################################################################################
Q4) Separate your inputs and outputs datasets into a training and a test set. Keep at least 20% of the dataset for testing.
Hint 1: You may use scikit-learn’s train_test_split function.
Hint 2: If you are considering optimizing the hyperparameters of your classifier, form a validation dataset as well.
Hint 3: We recommend performing the split on the indices so that it is easier to track what points are in which dataset after splitting. You will have an easier time when plotting the susceptibility map.
#####################################################################################################################
# 1. Import train_test_split()
#####################################################################################################################
from sklearn._______________ import train_test_split
#####################################################################################################################
# 2. Create a list with all indices in the input [0,1,2,...]
#####################################################################################################################
all_indices = list(range(len(inputs_gdf)))
#####################################################################################################################
# 3. Convert the inputs_gdf dataframe to numpy array
#####################################################################################################################
inputs_gdf = inputs_gdf.to_numpy()
#####################################################################################################################
# 4. Apply train_test_split on 'all_indices', and store training indices in 'indx_train', test indices in 'indx_test'
#####################################################################################################################
____,______ = _________________(____________,test_size=______,random_state=42)
#####################################################################################################################
# 5. Create training and test sets with indx_train and indx_test
#####################################################################################################################
____,____,___,___ = ____________[___________],_______[________],______[________],_______[__________]
# Check the shape of your training(/validation)/test sets
# and make sure you kept at least 20% of your dataset for testing
(396501, 16) (132168, 16)
Congratulations, you have created a viable wildfire dataset to train a machine learning classifier! 😃 Now let’s get started 🔥
3.5.1.2. Part II: Training and Benchmarking the Machine Learning Classifiers#
Q5) Now comes the machine learning fun! 🤖 Train multiple classifiers on your newly-formed training set, and make sure that at least one has the predict_proba method once trained.
Hint: You may train a RandomForestClassifier or an ExtraTreesClassifier, but we encourage you to be creative and include additional classifiers you find promising! 💻
#####################################################################################################################
# 1. Import RandomForestClassifier
#####################################################################################################################
from sklearn.__________ import RandomForestClassifier
#####################################################################################################################
# 2. Convert X_train and X_test into pandas DataFrame
#####################################################################################################################
X_train = ____________(_______)
X_test = _____________(_______)
X_train
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 545 | 15.253697 | 34 | 8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1 | 213 | 19.419361 | 32 | 8 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 484 | 22.660355 | 37 | 8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | 376 | 17.878534 | 32 | 8 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 1241 | 8.114972 | 32 | 26 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 396496 | 695 | 21.491549 | 34 | 15 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 396497 | 254 | 14.585821 | 32 | 8 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 396498 | 237 | 8.356695 | 32 | 8 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 396499 | 917 | 14.110499 | 33 | 15 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 396500 | 556 | 24.595417 | 32 | 8 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
396501 rows × 16 columns
#####################################################################################################################
# 3. Initiate RF classifier and fit it on training set
#####################################################################################################################
rfc = _____________
rfc.___(_____,_____)
RandomForestClassifier()
# (Optional) Conduct a hyperparameter search on the validation set
# e.g., using scikit-learn's RandomizedSearchCV
Q6) Compare the performance and confusion matrices of your classifiers on the test set. Which classifier performs best in your case?
Hint 1: You may use the accuracy_score to quantify your classifier’s performance, but don’t forget there are many other performance metrics to benchmark binary classifiers.
Hint 2: You can directly calculate the confusion matrix using scikit-learn’s confusion_matrix function.
#####################################################################################################################
# 1. Import accuracy_score, confusion_matrix, and ConfusionMatrixDisplay
#####################################################################################################################
from sklearn._____ import ___________
from sklearn.____ import _____________, ___________________
#####################################################################################################################
# 2. Use rfc to make prediction on test set
#####################################################################################################################
rfc_preds = rfc.________(_____)
#####################################################################################################################
# 3. Use accuracy_score to infer trained classifier performance
#####################################################################################################################
rfc_acc = ____________(_____, ________)
#####################################################################################################################
# 4. Plot the confusion matrix
#####################################################################################################################
cm = confusion_matrix(______, _______, normalize=____) # Get a confusion matrix 'cm', use 'pred' for the normalize option
disp = _________________(_____________ = cm) # Use ConfusionMatrixDisplay to visualize 'cm'
disp.plot()
For comparison, below is the confusion matrix obtained by the paper’s authors:

3.5.1.3. Part III: Making the Susceptibility Map#
Q7) Using all the classifiers you trained that have a predict_proba method, predict the probability of a wildfire over the entire dataset.
Hint: predict_proba will give you the probability of both the presence and absence of a wildfire, so you will have to select the right probability.
#####################################################################################################################
# 1. Predict the probability of a wildfire or not on the *entire* dataset
#####################################################################################################################
predprob_rf = rfc.________(_______) # Use .predict_proba in the 'rfc' classifier to process the entire dataset
#####################################################################################################################
# 2. Extract the probability of a wildfire happening over the entire period of the dataset for each instance
#####################################################################################################################
rf_testprob_fire = _______[____] # Hint: predprob_rf shape = [:,2], select the second column
Q8) Make the susceptibility map 🔥
Hint 1: The x and y coordinates for the map can be extracted from the variables dataset.
Hint 2: You can simply scatter x versus y, and color the dots according to their probabilities (c=probability of a wildfire) to get the susceptibility map.
# Scatter ['x'] vs ['y'] columns in the entire dataframe and color the dots with the predicted probability 'rf_testprob_fire'
# to make the susceptibility map
import matplotlib.pyplot as plt
fig,ax = plt._______(____,figsize=(6+5,4+2))
cmploy = ax.scatter(_________,_____________,s=5,c=____________,cmap='viridis')
plt.colorbar(cmploy,ax=___)
ax.set_title('Wildfire Susceptibility Map (RF)')
ax.set_ylabel('Y',size=13)
ax.set_xlabel('X',size=13)
ax.tick_params(axis='both', which='major', labelsize=11)
plt.show()
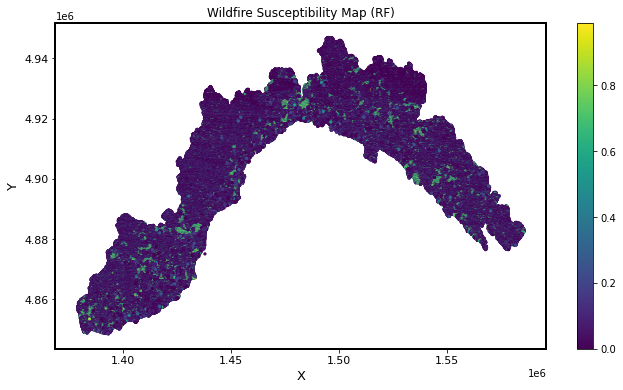
You should get a susceptibility map that looks like the one below. Does your susceptibility map depend on the classifier & the inputs you chose? Which map would you trust most?

It seems like our model was too simple to generate a useful map 😞 . Your TA actually experimented training a RandomForest model with 10 variables and got a 91% accuracy!
So you should definitely try combinations of different variables to get a map that is better than what you just got.
3.5.2. Bonus Exercise 4: Exploring the Susceptibility Map’s Sensitivity to Seasonality and Input Selection#

Caption: The Liguria region (Cinque Terre), after you save it from raging wildfires using machine learning ✌
3.5.2.1. Part I: Seasonality#
Q1) Using the season column of wildfires, separate your data into two seasonal datasets (1=Winter, 2=Summer).
Hint: When splitting your inputs into two seasonal datasets, keep in mind that temp_1 and prec_1 are the climatological mean temperatures and precipitation during winter, while temp_2 and prec_2 are the climatological mean temperature and precipitation during summer.
# Identify indices for which the wildfires occured during winter/summer
# Use these indices to split your `inputs` and `outputs` datasets
# into two seasonal datasets
# Verify that for each season, the shape[0] of your
# `inputs` and `outputs` sets are the same
Q2) Use these two seasonal datasets to make the Liguria winter and summer susceptibility maps using your best classifier(s). What do you notice?
Hint: Feel free to recycle as much code as you can from the previous exercise. For instance, you may build a library of functions that directly train the classifier(s) and output susceptibility maps!
# So
# Much
# Recycling
# Compare the winter and summer susceptibility maps
3.5.2.2. Part II: Input Selection#
The details of the susceptibility map may strongly depend on the inputs you chose from the variables dataset. Here, we explore two different ways of selecting inputs to make our susceptibility maps as robust as possible.
Q3) Using your best classifier, identify the inputs contributing the most to your model’s performance using permutation feature importance.
Hint: You may use scikit-learn’s permutation_importance function using your best classifier as your estimator.
# Import the necessary functions and classes
# Calculate the permutation importance of each of your model's inputs
# Display the result and identify the most important inputs
Q4) Retrain the same type of classifier only using the inputs you identified as most important, and display the new susceptibility map.
Hint: Feel free to recycle as much code as you can from the previous exercise. For instance, you may build a library of functions that directly train the classifier(s) and output susceptibility maps!
# Lots
# of
# recycling
# Make the new susceptibility map
Can you explain the differences in susceptibility maps based on the inputs’ spatial distribution?
If the susceptibility map changed a lot, our best classifier may initially have learned spurious correlations. This would have affected our permutation feature importance analysis, and motivates re-selecting our inputs from scratch! 🔨
Q5) Use the SequentialFeatureSelector to select the most important inputs. Select as few as possible!
Hint: Track how the score improves as you add more and more inputs via n_features_to_select, and stop when it’s “good enough”.
# Import the SequentialFeatureSelector
# Add more and more inputs
# How many inputs do you need to get a "good enough" score?
Which inputs have you identified as the most important? Are they the same as the ones you selected using permutation feature importance?
Q6) Retrain the same type of classifier using as little inputs as possible, and display the new susceptibility map.
Hint: Feel free to recycle as much code as you can from the previous exercise. For instance, you may build a library of functions that directly train the classifier(s) and output susceptibility maps!
# Recycle your previous code here
# and here
# And remake the final susceptibility map
How does it compare to the authors’ susceptibility map below?